Fine-tuning and Evaluating LLMs - Databricks
Databricks Summary
Table of Contents
Exploring Fine-Tuning for LLM Performance with GPU Acceleration | 0:00:00 - 0:00:40
https://youtu.be/2vEpMb4ofVU?t=0 This notebook in module 4 explores fine-tuning for LLM performance using a GPU to speed up the process. It highlights the use of Microsoft’s DeepSpeed technology for running code on single and multi-GPU setups on single and multi-node configurations. The focus is on optimizing LLM performance for specific tasks through fine-tuning, with a recommendation to use a GPU for faster processing.
Setup for Fine-Tuning T5 Small LLM | 0:00:40 - 0:03:00
https://youtu.be/2vEpMb4ofVU?t=40 We are going to fine-tune the T5 small LLM and use it to classify movie reviews as either positive, negative, or neutral. For our first step, we will check if we are running our cluster with a GPU. If no output is received from this assert statement, it means we are good to continue.
Next, we need to download some CUDA library installations from the NVIDIA website. We will do this by running the following cell. These CUDA libraries will also be installed in our workspace.
Subsequently, we need to install DeepSpeed. We can confirm that our classroom setup is working correctly by checking our username and our working directory.
Once this is all done, we can proceed. We will continue navigating through our notebook and confirm that our classroom setup is in place. We will create a new book and a temporary file to store the outputs of our model checkpoints.
Now we can commence with the fine-tuning process. We will use the Pandas library and also transformers and datasets from Hugging Face. In the first step, we want to verify that our data is in the correct format for fine-tuning our model. We will download the IMDB dataset, which is a collection of movie reviews tagged either as positive, negative, or neutral.
Additionally, we have a pre-trained model, the T5 family model, which we will utilize. We have explored this model in this class, and we will be examining it more in the future. The T5 family model is a robust model capable of performing various tasks.
The plan is to use the T5 small version with around 60 million parameters as the model checkpoint. Additionally, a tokenizer will be downloaded to convert the text into the appropriate token set for the T5 model.
Be cautious about the format of labels in the IMDB dataset, which uses numerical values for sentiment. Convert these numerical labels into natural language equivalents to utilize the natural language aspect of the workflow. Functions will be written to convert the data labels to text labels. After labeling the dataset with natural language sentiments and tokenizing it, prepare for training by setting up the training process using the training arguments class from Hugging Face. The training will involve one epoch over the training data, sending 16 entries per optimization step using the AtomWtorch optimizer.
Utilize TensorBoard to visualize the model. Load the model for sequence-to-sequence language modeling from Hugging Face’s auto model, specifically using the T5 small model checkpoint. Note the option to switch to a different type of T5 model if desired.
Setting up the Trainer for Model Training | 0:05:25 - 0:09:20
https://youtu.be/2vEpMb4ofVU?t=325 The subsequent step involves configuring the trainer to utilize the model, the training arguments, and the tokenized dataset. A data collator is employed to guarantee data preparedness for GPU processing. The training will subsequently undergo progression from the foundational model to a refined version. TensorBoard will be utilized to monitor the progress of the training.
The app’s training process has not yet commenced; however, more information will be displayed as updates are implemented. The subsequent step entails initiating the training process, with a focus on refining the model through additional training from the previous checkpoint. The optimizer is employed to minimize prediction errors, specifically in predicting positive, negative, or unknown sentiment labels for movie reviews.
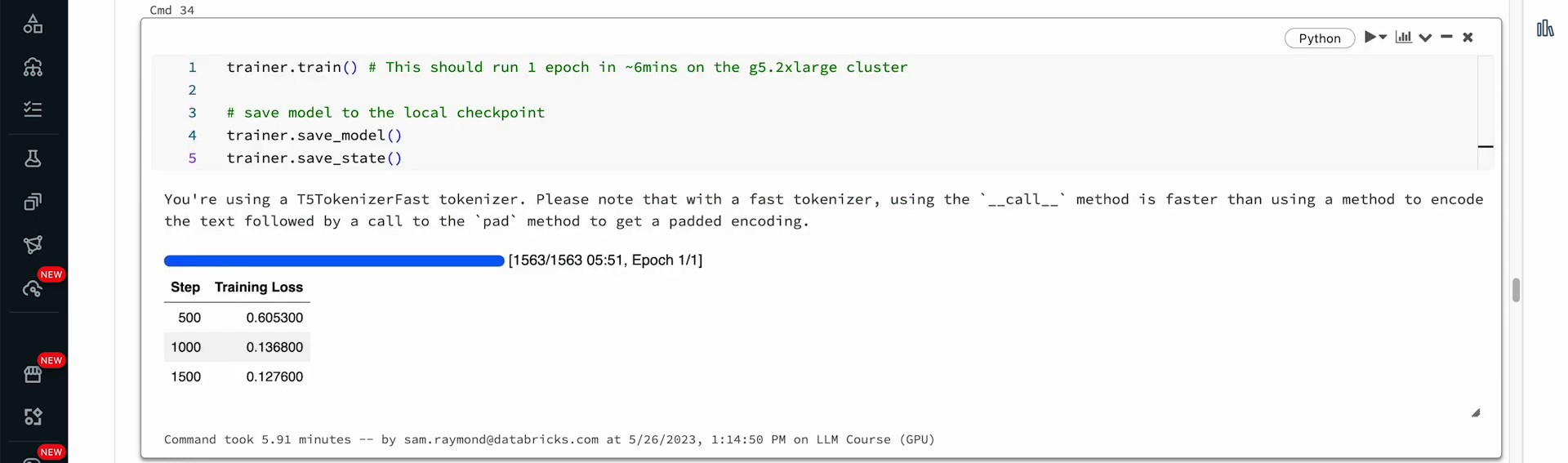
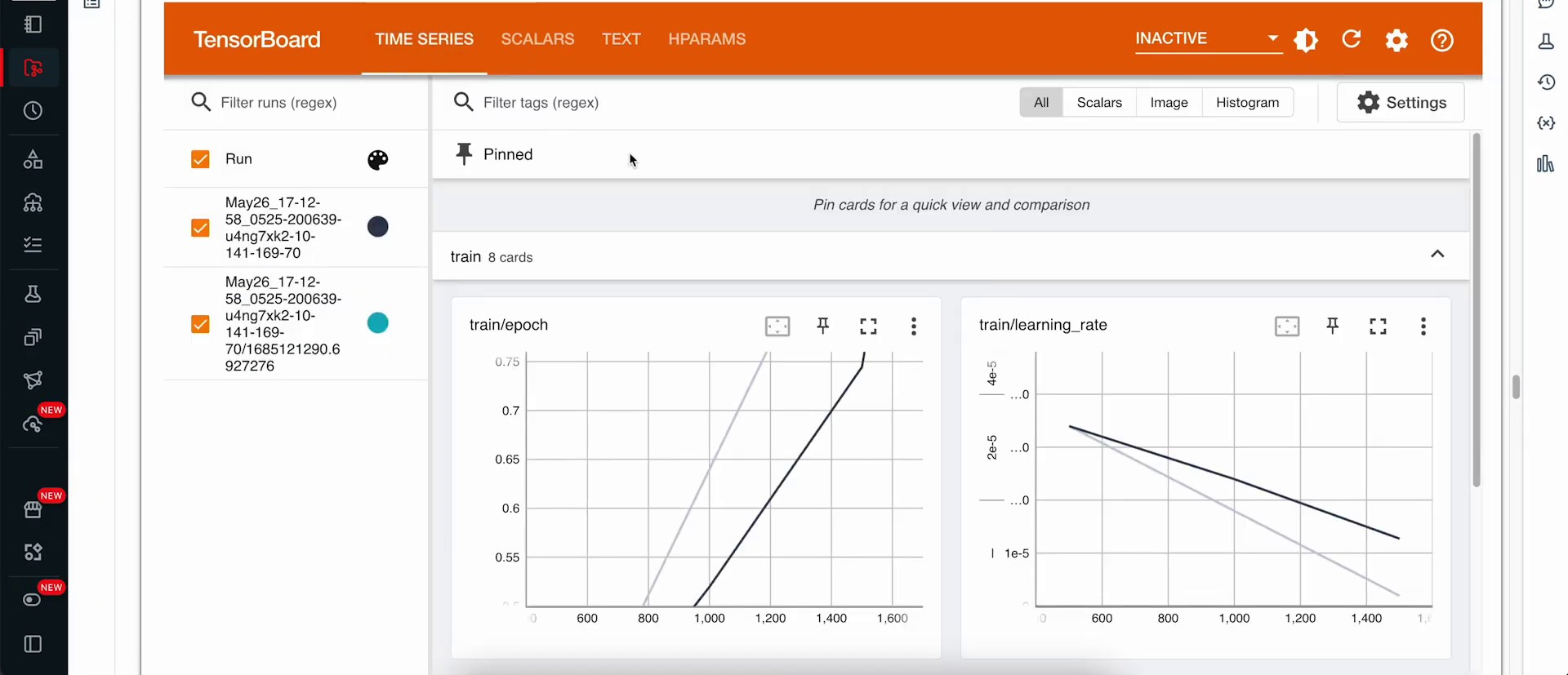
We intend to execute ‘trainer.train’ and run it for one epoch. Subsequently, we will save the model and the state. This process will require approximately five to six minutes. We can now observe that our training has completed the 1500 steps required to finish a full epoch of our data. Let’s backtrack to TensorBoard. If we proceed and examine the graphs depicting the performance, and scrutinize our training loss while switching it to a log scale, we might observe that we could still conduct further training to decrease the training loss. However, we have reached a satisfactory point for now and aim to proceed to the next part. Here, we will save the model to the Databricks file system (DBFS).
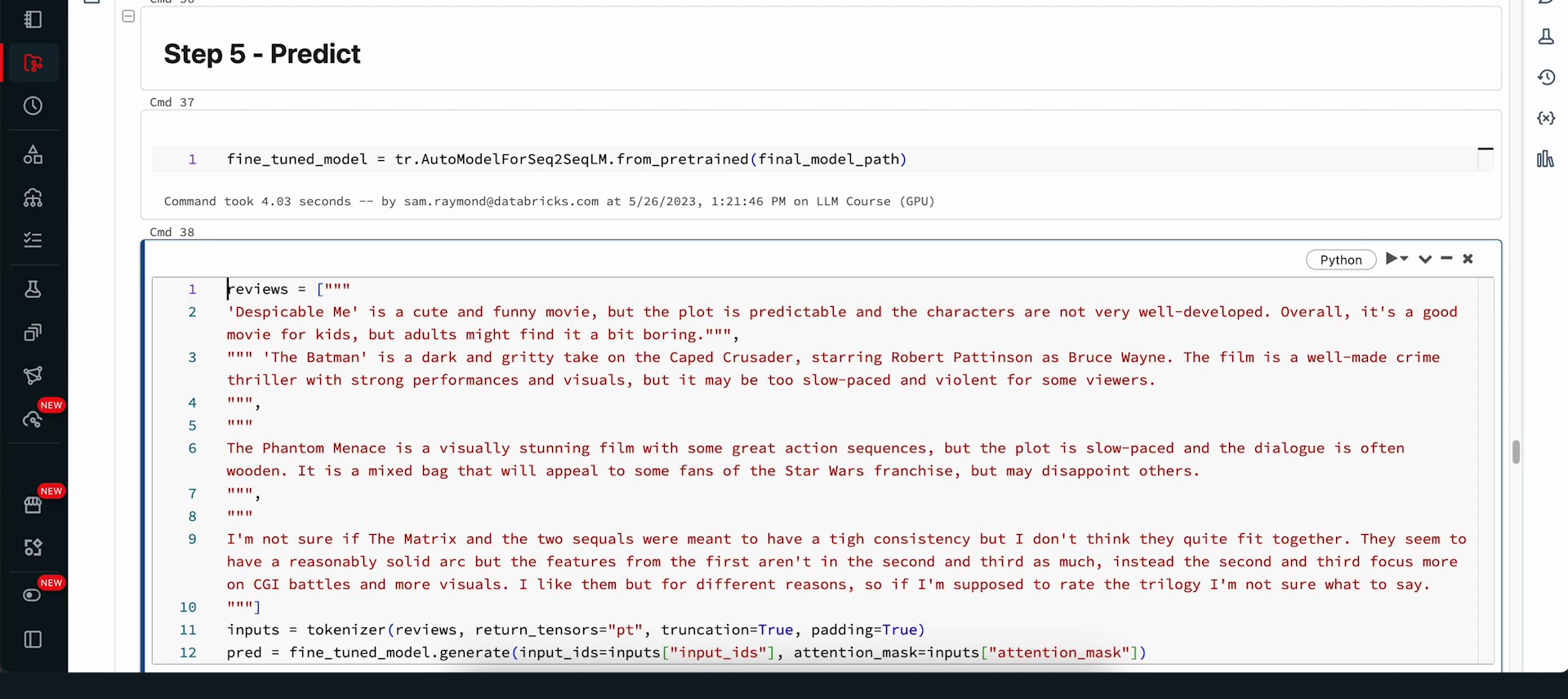
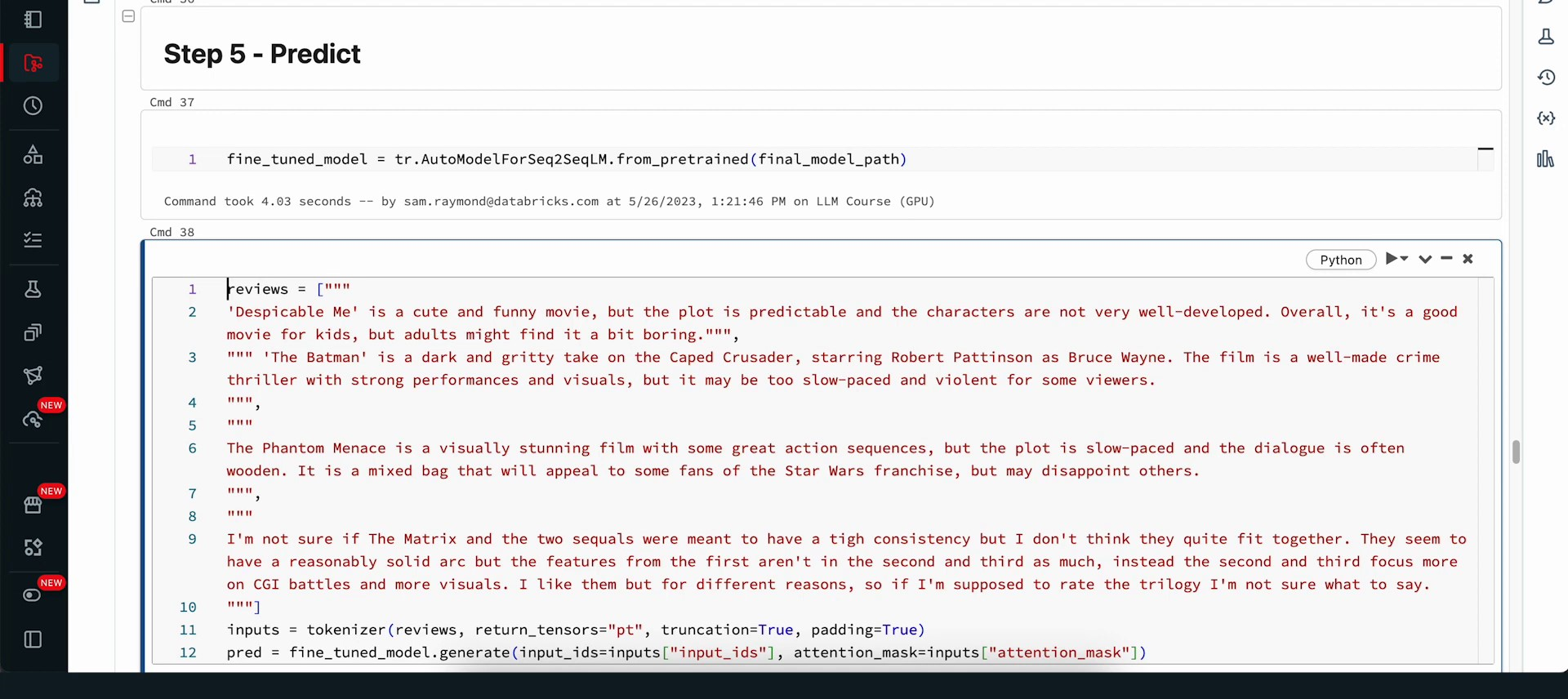
Our next step is to utilize this refined model for prediction. We will implement the DBFS model and load it as our refined model for inference. We have an array of movie reviews that each express differing sentiment types. Please take a moment to read through these reviews and ponder the movie’s narrative and the sentiment expressed - whether positive, negative, or ambiguous. Subsequently, we will translate all these reviews into tokens and have our model interpret them. The model’s predictions will then be stored in line 12 using the dot generator.

After running this cell, we will process these reviews through our model. Next, we will compile all the predictions within our tokenizer and perform decoding so that all the information is located in one place, converting the tokens from numerical values to plain text. We will merge this into a new pandas data frame and view the classification for each review. As we can observe, the initial classification was negative, the following two were positive, and the final one was negative.
Introduction to DeepSpeed for Running Fine-Tuning Models on Small T5 Model with Single GPU | 0:09:20 -
https://youtu.be/2vEpMb4ofVU?t=560 You can decide for yourself whether or not you think these reviews were processed well, but, in my opinion, they were. Currently, let’s discuss DeepSpeed. The fine-tuning model was run on one of the smallest T5 models–T5 small–using a single GPU. In many circumstances, we might find that our models do not fit into the device memory, or we simply need more computing power to conduct our fine-tuning in a reasonable amount of time.
To enable us to run on multiple GPUs and multi-node, multi-GPU clusters, we need to utilize special software. DeepSpeed, a product of Microsoft, allows us to carry out these tasks. We run this software on a single node, single GPU instance; however, please keep in mind that it’s not designed for this type of work. Changing some of the environment variables we’re about to present to you and re-running the code using the DeepSpeed command is all you need to do. We’ll run this again only for demonstrative purposes, but remember that we need to execute this in a unique mode to operate on our server, which is a single GPU, single device.
In this section, we look at the configuration options for Zero Optimization targets in multi-GPU setups. We follow a similar process to establish the model, convert the dataset into tokens, and load the T5 small model checkpoint. Two principal changes applied to the training setup are: using a distinct checkpoint name to prevent overwriting the fine-tuned model and adding the DeepSpeed configuration as an additional variable in the training arguments from HuggingFace. This adjustment provides a wrapper around the DeepSpeed framework.

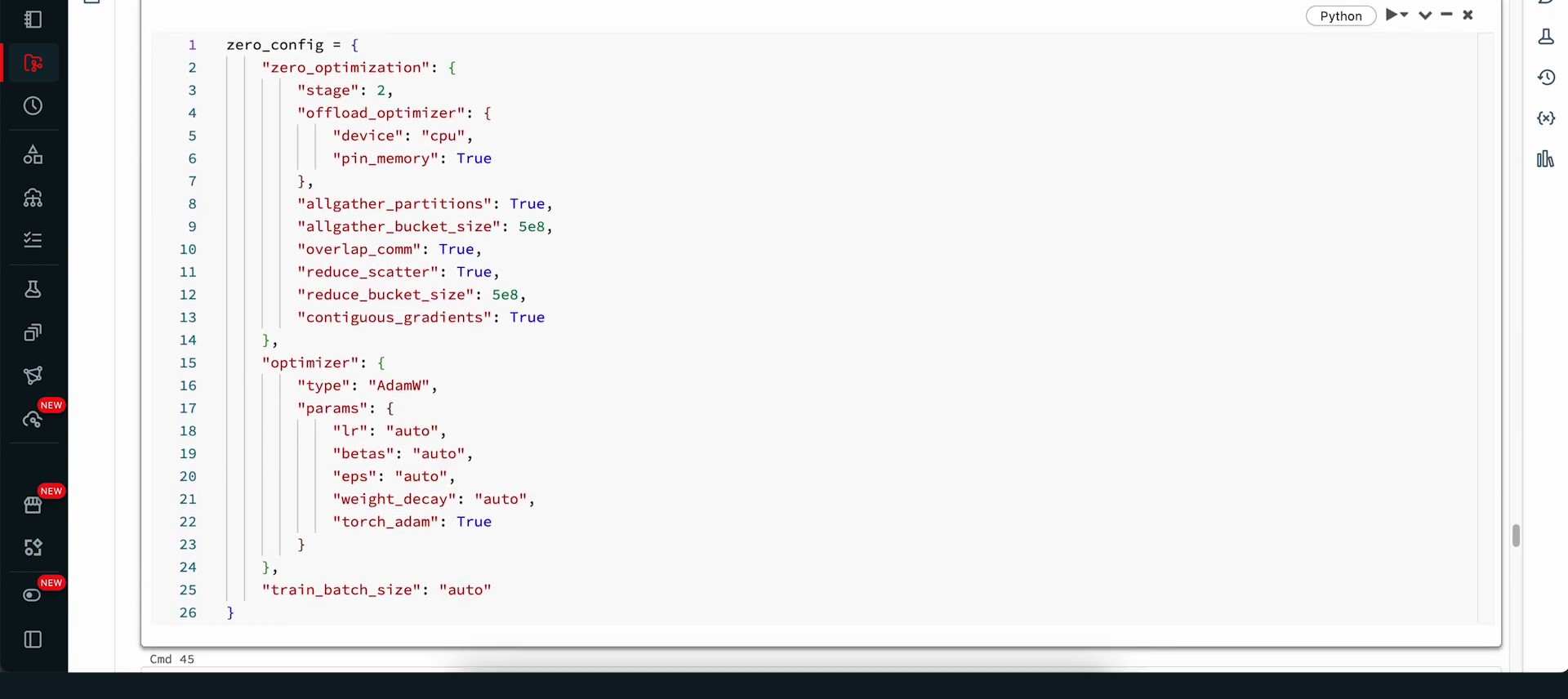
The training process comprises one epoch characterized by the same batch size, and it incorporates the DeepSpeed Zero configuration. The trainer is set up using the training arguments and the dataset, utilizing TensorBoard for monitoring purposes. The trainer operates in a manner similar to earlier methods, with additional output from DeepSpeed as it configures itself.
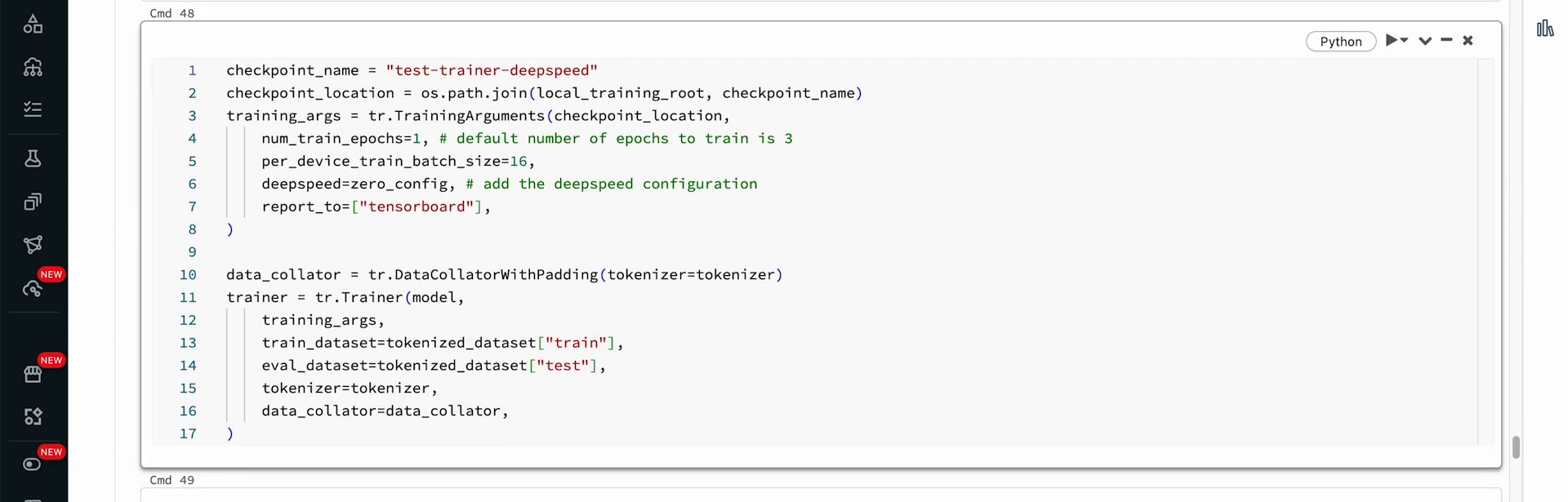

When you use DeepSpeed on a cluster configuration not optimized for it, additional overhead is experienced due to communication between nodes and devices. This overhead results in extended training times compared to normal fine-tuning. Despite the extended training time, the same state of training loss and steps can be achieved. The process requires saving the model, loading it for predictions, generating model predictions, decoding the output with a tokenizer, and examining the classification.
DeepSpeed streamlines the process of fine-tuning with minimal code changes, offering a glimpse of its capabilities. To fully exploit DeepSpeed, additional hardware and resources are required. This demonstration showcases conventional fine-tuning of Large Language Models, transforming T5 small into a tool for movie review sentiment analysis. The next step is evaluating the fine-tuned models to confirm that they produce the desired results. This overview forms the foundation for more exploration in the subsequent notebook.



Evaluating Performance of a Large Language Model | 0:00:00 - 0:11:00
https://youtu.be/6MyKbmylAjA?t=5 The video discusses the process of evaluating the summarization task for a large language model using the Rouge metric. It explores building and comparing different models of varying sizes to evaluate their performance. The setup involves installing necessary libraries to begin the task.
How can you determine if you’re creating satisfactory summaries for these articles? For instance, if you’re developing a smartphone application requiring on-the-go, automated summary generation, it’s crucial to ascertain how well your model performs. This article will guide you through how we can approach this, develop an understanding of how Rouge works, and implement it.
We will utilize a dataset from CNN Daily Mail, available for review at the Hugging Face Datasets Library. This source provides us with news pieces accompanied by highlights or summaries. We will employ these pre-produced summaries as our reference materials.
We’ll import data using the datasets library from Hugging Face, pulling in just 100 samples to expedite the analysis. If you attempt this out of this notebook context, downloading more datasets can dramatically extend the time, as they are stored locally in a cache directory to speed up the process.
As you can note, there’s a user warning indicating that large dataset downloads can be time-consuming. But this process won’t take long since we’ve preloaded a significant part of this data. Now that we’re prepared, let’s review the downloaded data set. Each article comes with a summary in a column labeled ‘highlights’. Let’s randomly pick an article and its highlight for review.

Now let’s move on to how summarization works and how to utilize our massive language model. The Transformers AutoTokenizer and T5 for conditional generation libraries will be downloaded for the T5 model. The next step is to develop a function to aid in creating this pipeline.
The Rouge score, which examines generated summaries against reference summaries by performing unigram, bigram, and trigram analysis, needs to be recalled here. We’d show you how you’d construct your pipeline to conduct this examination from scratch.
First, a batch generator is designated, taking in our data set and a batch size. It will employ the yield statement to output batches until we’ve exhausted our data set. The next function is summarization performed using the T5 model. A model checkpoint, a list of articles, and a batch size are passed here. The T5 model is used to compute the summaries here, which can be a T5 base or T5 large, depending on our requirement.
Although we’ll run this on a CPU for this notebook, codes can enable this to run on a GPU. The T5 for conditional generation will define our model, and our tokenizer will convert input into tokens, passable into the model, and convert the model output back to plain text. We will define our sequence input length as a maximum model length of 1024 and then the model length.
The inference performance will use our massive language model, forming inputs using the built tokenizer. The batch of data for the article will be passed to the tokenizer, indicating the maximum input length. We’re also declaring here that PyTorch will be used instead of TensorFlow. Adding padding equal to true means padding the remaining tokens with a skip token if the input has less than 1024 tokens length. If it exceeds 1024 tokens, the tokenizer truncates the input, losing some information. The model and tokenizer are then used to generate outputs, stored in summary IDs.
The process involves using a tokenizer to decode and passing in summary IDs generated from a large language model to return plain text. The function initializes a response array and fills it by adding prompts for the model to summarize. Batches are processed using a batch generator, and all summaries are appended to the array. To manage GPU memory, the cache is emptied and garbage collection is used. After completing runs, the tokenizer, model, and other resources are deleted to free up memory. The function returns the response with the article summaries. In summary, the function outlines the process of summarizing models with T5, including batch generation, data formatting, model configuration, inference, and output conversion. T5 small and T5 base models are utilized for the task.




The T5 large model is a type of transformer model that is compatible with the T5 architecture. It is one of the models that can be used with this architecture for various natural language processing tasks.
T5 models, such as T5 Small, T5 Base, and T5 Large, can be used for conditional generation, such as summarizing a sample article using T5. The output response array from these models can be compared to the original article. Afterwards, the summaries can be analyzed to assess the quality of the summaries created by the model by looping through all reference summaries.
Evaluation of Summarization Models with the Rouge Metric | 0:11:00 - 0:20:20
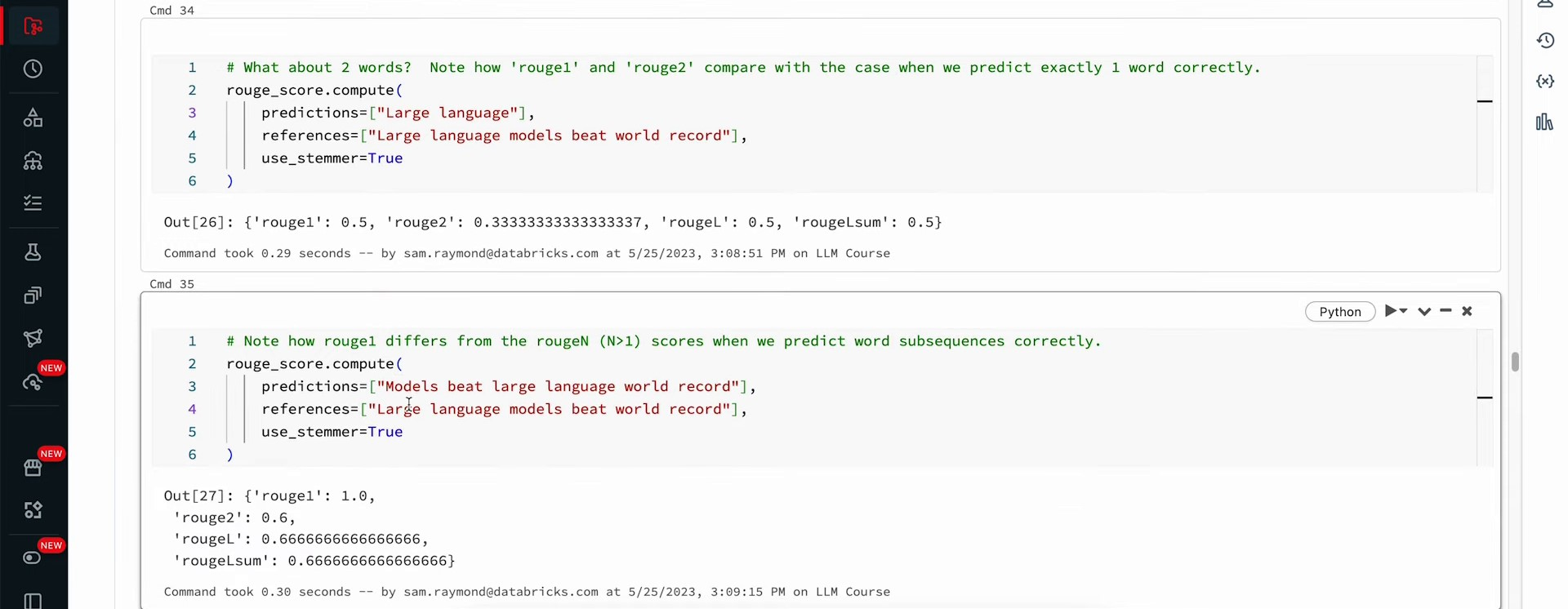
https://youtu.be/6MyKbmylAjA?t=660 We’re going to examine T5 summaries and reference summaries. If a generated summary precisely matches the reference summary, it receives a score of one. If not, it scores zero. Before running this, consider the likelihood of perfect matches between both, or minor differences. Any discrepancy results in a value of zero; perfect matches score a one. Let’s check it out: we got 0.0. Hopefully, you anticipated zero accuracy since the probability of summaries matching references exactly is infinitely small. Slight wording variations make this strategy untenable for assessing our summarization performance. Enter Rouge.
Rouge compares subparts of our summaries and reference summaries. It comprises four different scores: Rouge1, Rouge2, RougeL, and RougeLsum. Rouge1 assesses unigrams, or single words/tokens, checking for their occurrence in the generated summary. Rouge2 evaluates bigrams, word/token pairs. RougeL analyzes the longest shared subsequence between summaries, and RougeLsum examines the entire summary level, disregarding sentence breaks or new lines.

Let’s import the Rouge library and assess our model’s performance with summaries. We’ll need two pieces here: downloading the NLTK library and calculating the Rouge metrics via Hugging Face’s evaluate library. The correct format separates sentences with new lines for comparison. To do so, we’ll create a wrapper function—computeRougeScore—which takes a list of generated and reference summaries as inputs. Within the function, we employ NLTK’s sentence tokenization function to join sentences with newline characters, ensuring input is in the correct format for Rouge evaluation. Following input formatting, we compute the Rouge score using the scoring function and set useStemmer to true.

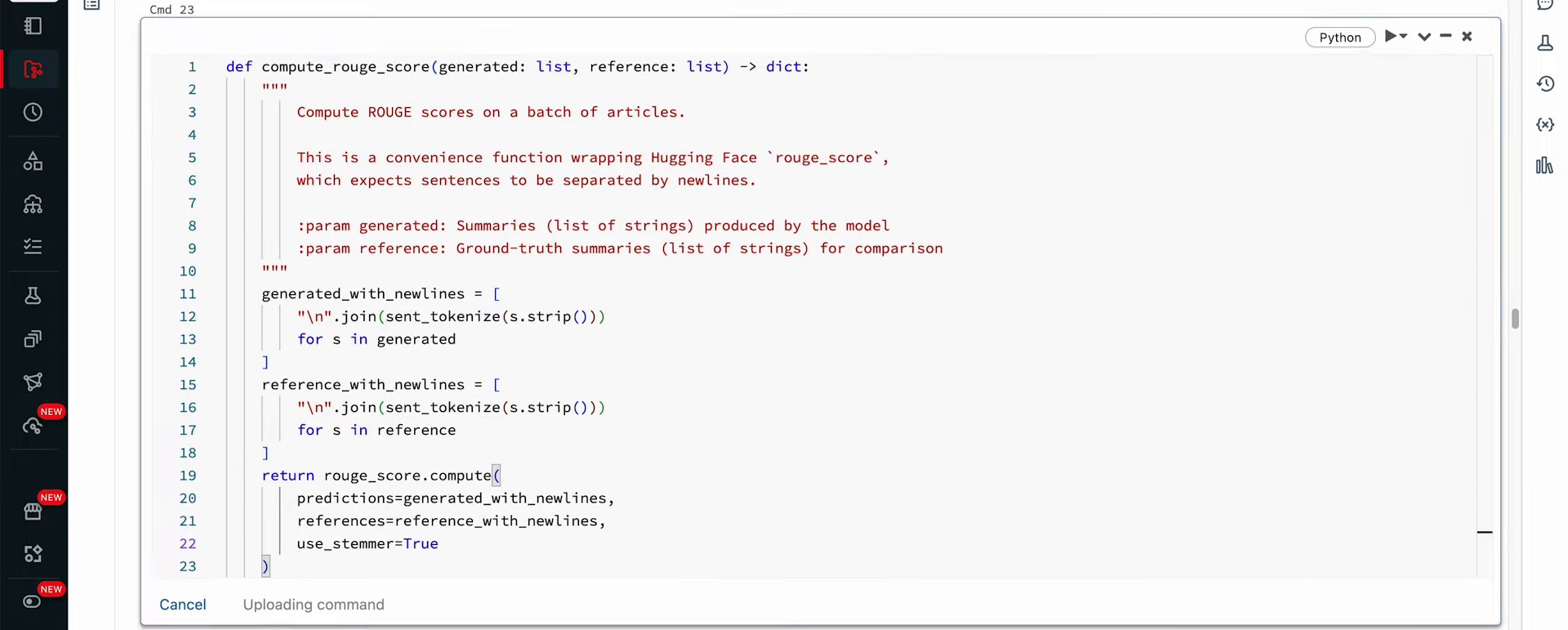
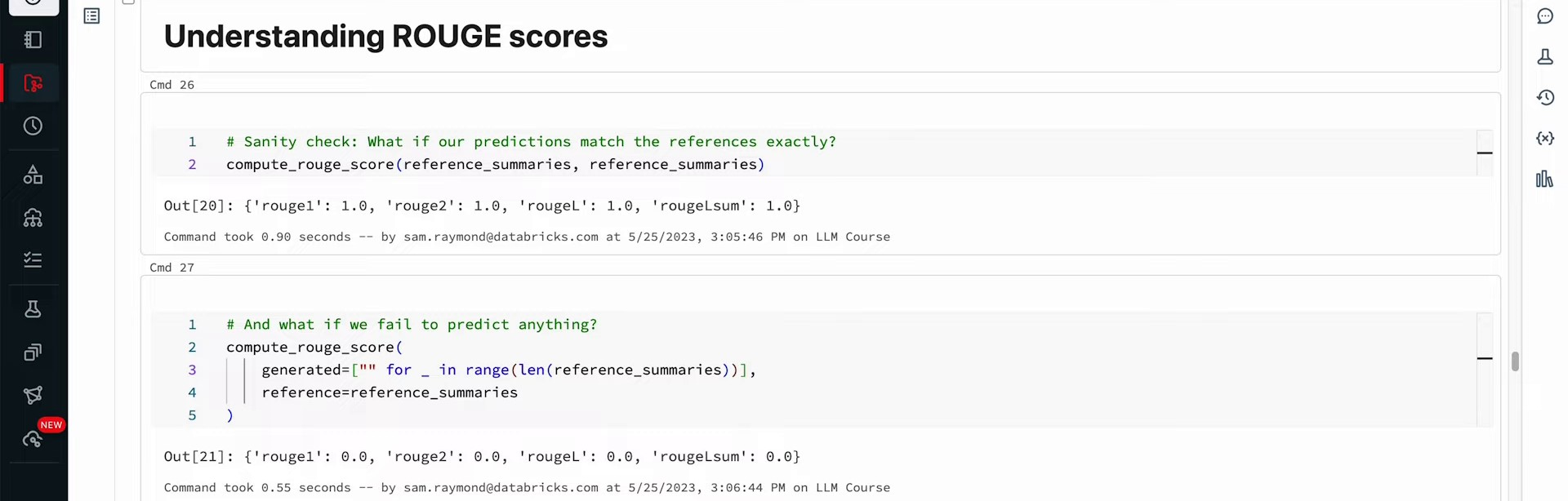
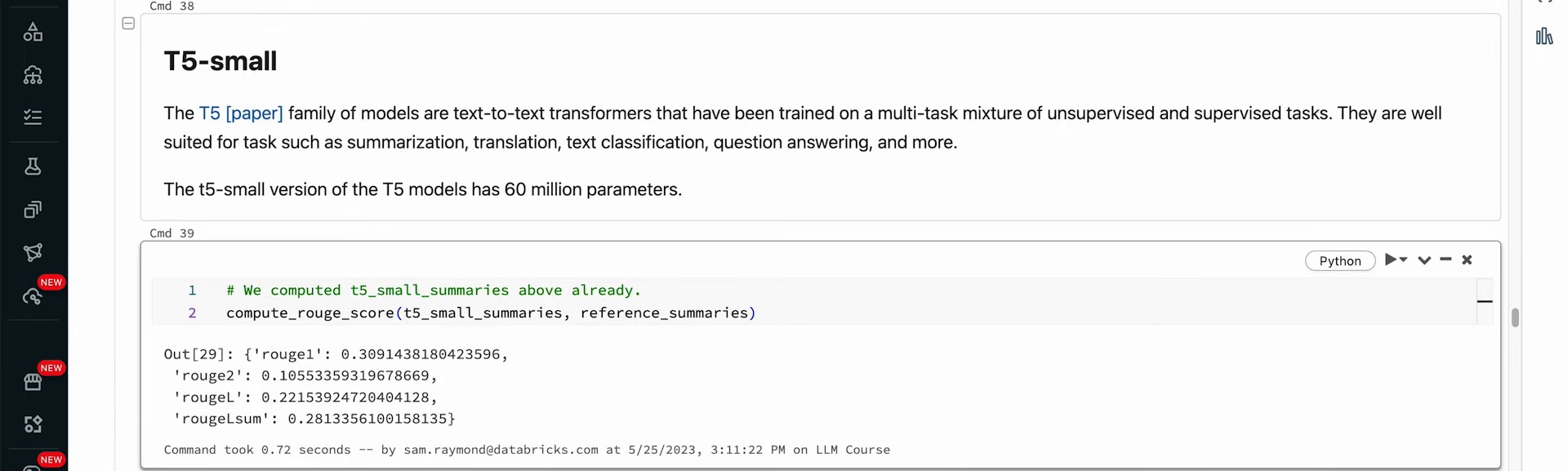
Running this function offers Rouge values for the T5 small model. Rouge1 scores indicate that approximately 31% of unigrams are common in generated and reference summaries, while bigram overlap reduces to 10%. Longest running subsequences score about 0.2, and the cumulative summary score hovers around 0.3. While these scores represent fair performance for a small LLM, a larger model could offer potential improvement. Reference summary self-comparisons yield perfect scores, indicating an excellent match. However, a perfect match with reference summaries doesn’t imply flawless performance of your model, but rather good alignment with the references.
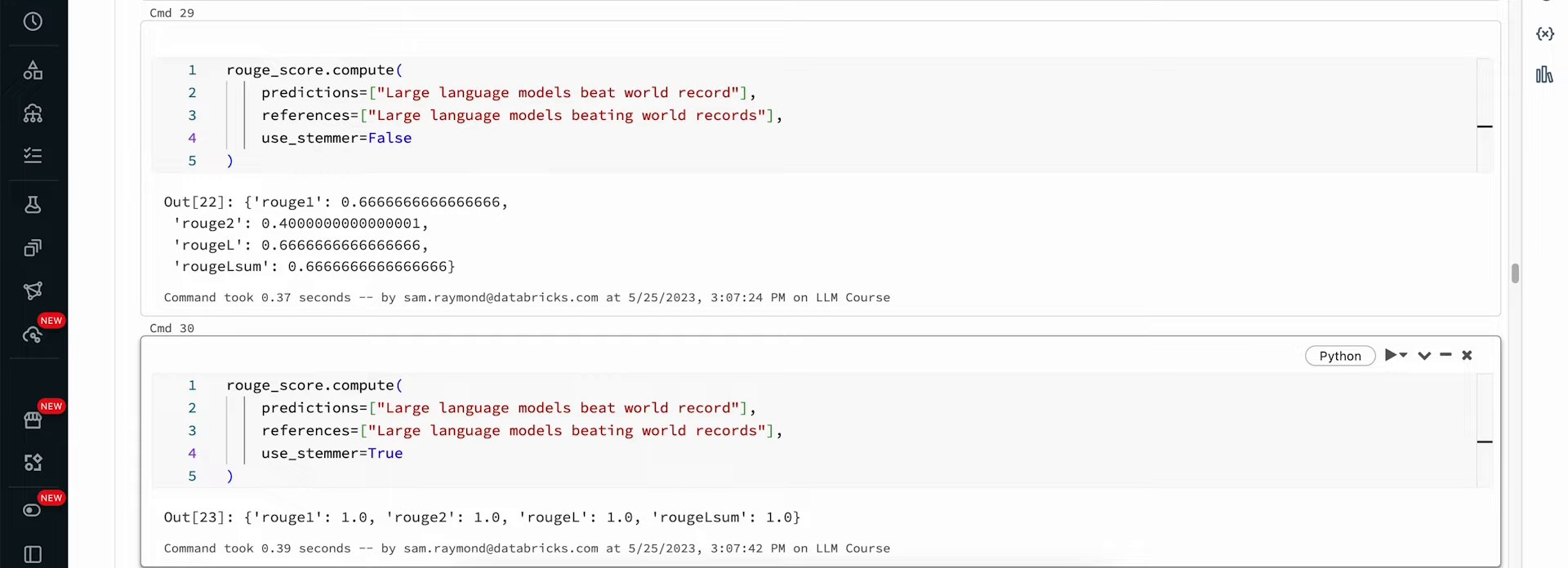
When working with large language models or any part of machine learning, it’s crucial to ensure the quality of the data used. Perfect scores don’t indicate a flawless model; they often signal underlying issues. In the context of evaluating model output, the lowest score reflects an empty reference summary. The Rouge metric assigns scores between zero and one, considering minor word variations through stemming. For instance, ‘large language models beat world record’ and ‘large language models beating world records’ demonstrate minor differences in words like ‘beat’ and ‘beating’ and ‘record’ and ‘records’.
When the stemmer is set to false, the Rouge scores are 67% for Rouge one and 40% for Rouge two. However, when stemming is turned on and differences are ignored, perfect scores are achieved. The interpretation of these scores as being different or similar is subjective and part of the art in language modeling. Rouge scores can vary in different situations, such as when the reference contains one word but the prediction is much longer.
Rouge provides a relatively decent score for Rouge 1 but zero for Rouge 2 due to the lack of bigrams for comparison. The Rouge score is symmetric in terms of predictions and references, giving the same value even if the lengths are different. By creating a two-word prediction matching the summary, higher values are obtained for Rouge 1, Rouge 2, Rouge L, and Lsum. Rouge 1 matches every word but does not consider word order, making it a potentially misleading metric. Larger values in Rouge metrics account for word order and improve evaluation accuracy.
Rouge 2, Rouge 3, and Rouge L are important tools for ensuring high-quality results in evaluating subjective content. Another useful comparison method is to analyze the differences between small and large versions of the same model family, such as the T5 small model.
Comparison of T5 Small, T5 Base, and GPT-2 Models for Summarizing Articles | 0:20:20 -
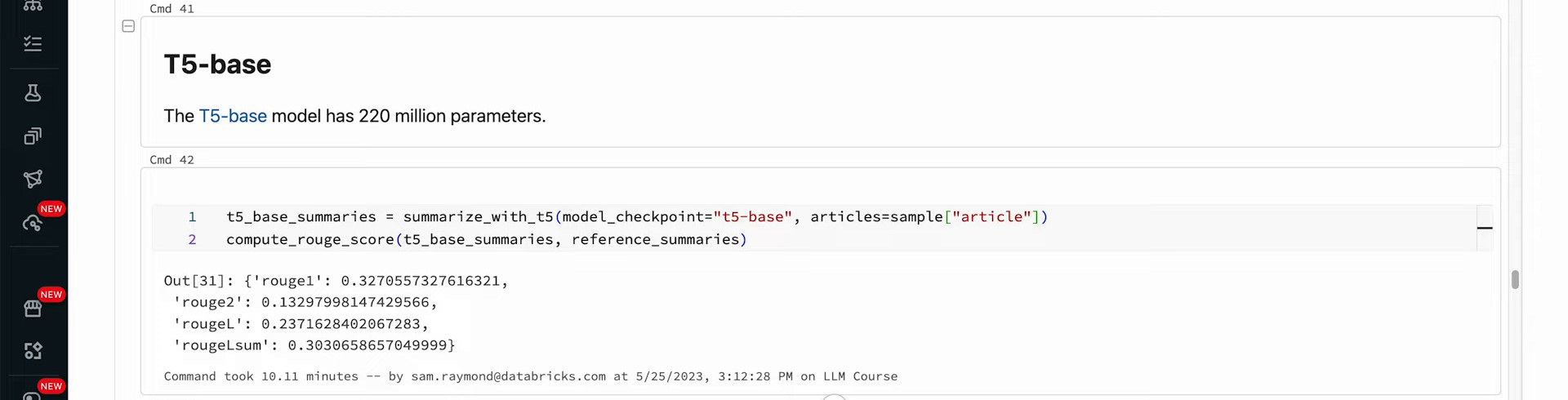
https://youtu.be/6MyKbmylAjA?t=1220 In this video, we discussed the use of different models like T5 Small, T5 Base, and GPT-2 for summarizing articles. We created a new function to compute Rouge scores per row to evaluate the performance of each model. T5 Small, with 60 million parameters, was compared to T5 Base, which has 220 million parameters and showed better Rouge scores. The T5 models are encoder-decoder models, while GPT-2, with 124 million parameters, is a decoder-only model. We explored how each model performed in generating summaries and observed improvements in Rouge scores with the larger T5 Base model. The discussion highlighted the differences in model architectures and their impact on summarization tasks.

In this task, we are creating a summarize function using a GPT-2 type model. The process involves passing a checkpoint, articles, and batch size, similar to the T5 model. However, the input format for GPT models varies across different architectures. The tokenizer used here is slightly different from the previous one but serves the same purpose. The model being downloaded is the GPT-2 model. For inference, a performInference function will be defined, taking inputs as tokens from the tokenizer.



The batch function can be used to split data into batches. It is important to provide a prompt to the tokenizer and model when using GPT, as it completes sentences and generates new data based on the prompt given.
The process of generating article summaries using GPT-2 involves using a prompt string, ‘tldr’, instead of a specific command like in T5. Summary IDs are created and converted back into plain text using the tokenizer’s decoder. Post-processing involves extracting the summary after the ‘tldr’ statement to avoid including the entire article. Memory usage is optimized before using GPT-2 to generate the summaries. Evaluation is done using Rouge scores to assess the quality of the generated summaries.

In comparing the performance of T5 small, T5 base, and GPT-2 on a dataset, T5 base emerges as the best performer while GPT-2 lags behind. GPT-2 was trained to predict the next word based on text, while T5 was trained on various tasks including summarization. When analyzing the summaries produced by each model, T5 base outperforms the others consistently. However, GPT-2 sometimes gets stuck in loops, producing repetitive outputs. This highlights the importance of not just accuracy and perplexity scores, but also the relevance of the generated text. For example, GPT-2 may produce technically correct but nonsensical outputs. T5 small and T5 base also have their inaccuracies, with T5 base performing relatively better. Exploring different models for better evaluation is encouraged. The next module will focus on the interaction between large language models and society, emphasizing the need for ethical and safe application of this technology.